【NLP】Named Entity Recognition 未完待续
NER
Wikipedia
Named-entity recognition (NER) (also known as (named) entity identification, entity chunking, and entity extraction) is a subtask of information extraction that seeks to locate and classify named entities mentioned in unstructured text into pre-defined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, percentages, etc.
Most research on NER/NEE systems has been structured as taking an unannotated block of text, such as this one:
Jim bought 300 shares of Acme Corp. in 2006.
And producing an annotated block of text that highlights the names of entities:
[Jim]Person bought 300 shares of [Acme Corp.]Organization in [2006]Time.
In this example, a person name consisting of one token, a two-token company name and a temporal expression have been detected and classified.
State-of-the-art NER systems for English produce near-human performance. For example, the best system entering MUC-7 scored 93.39% of F-measure while human annotators scored 97.60% and 96.95%.
维基
命名实体识别(NER)任务是信息抽取领域内的一个子任务,其任务目标是给定一段非结构文本后,从句子中寻找、识别和分类相关实体,例如人名、地名和机构名称。
在自然语言处理领域,通过分析文本从而实现有价值信息抽取的过程,被称为信息抽取(information extraction,IE)。语义知识丰富度的提升给阅读理解 、自动问答和机器翻译等任务带来了进一步的效果的提高。
历史
The Sixth Message Understanding Conference (MUC-6)首次提出 NER。
在 MUC-6 上提出需要提取的实体是:people, places, and institutions。
接着把地区细分为 countries, provinces, states, and cities。
对于人物,可以细分为 politicians, actors, and other roles。
实体归为两类:generic(通用类)和 domain-specific(特定领域类)。
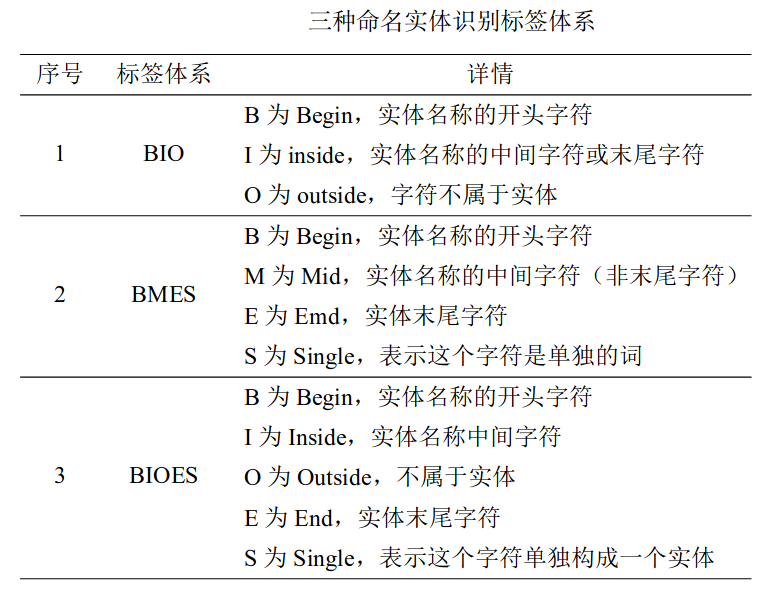
![]()
基于规则和词典
早期 NER 技术的发展还不成熟。
基于规则的方法是通过人工构建规则和模板来进行的。在 1990 年代初期,Rau 将基于模板和规则的方法应用于命名实体识别任务,但是这种方法需要领域专家自定义规则,耗费时间和精力,不能应用于其他领域,泛化性和可移植性较差。
基于词典的方法则需要包含了大规模实体信息的词典作为支撑。对词典中的未登陆词进行匹配等。
基于机器学习
在将机器学习应用于命名实体识别任务后,领域专家不再需要手动构建规则或模板,而是依靠带注释的语料库来训练模型。命名实体识别本质上可以视为一个序列标注问题,代表模型包括隐马尔可夫模型和条件随机场模型。
基于深度学习
与机器学习相比,基于深度学习的实体识别在一定程度上降低了对特征的依赖,解决了模型训练中的误差传播问题。卷积神经网络(CNN)、循环神经网络(RNN)及其变体网络是该方法的主要实现。卷积神经网络在命名实体识别任务中的应用,最初是由 Collobert 在 2019 年提出的。同年,国内学者在 CNN 的基础上增加了 CRF,提出了 CNN-CRF 模型,用于从中国电子案例中提取实体。使用此模型后,准确性和速度都得到了提高。
RNN 网络在处理文本序列有着其优势,但也面临着几个亟待解决的问 题。RNN 网络只能学习到与当前时刻相对较近的位置的特征,距离较远的特征 在循环过程中无法保存下来。且由于 RNN 本身的特性,在训练长序列时,会出 现梯度消失和梯度爆炸的问题。为此,Schmidhuber 等人提出了长短时记忆网络 (LSTM)。
LSTM 网络通过细胞结构来决定记住或遗忘哪些状态,成功的解决了 原始 RNN 无法保存远距离特征的缺陷,而且解决了梯度消失的问题。后来有研 究人员在 LSTM 中添加了反向的 LSTM,使其成为 BiLSTM,可以更好的捕获双 向语义。结合 CRF,形成了基于 Bi-LSTM-CRF 的命名实体识别 框架。然而由于 LSTM 天生的结构问题,其无法并行的弊端一直亟待解决。
基于预训练模型
在 NER 里面,可以使用预训练词向量模型来代替字符的向量表达。早期的预训练 技术是词嵌入技术。在 2013 年,进行词嵌入的主要工具是 Word2Vec。这是一 种强大的词向量嵌入技术。然而,使用 Word2Vec 等 Word Embedding 方法无法区 分同一个单词的不同含义。相同的单词经过 Word2Vec 训练后会得到相同的向量 表达。在进行命名实体识别任务时,可能会因为无法区分一个词的不同含义而导 致识别错误。
为了解决这个问题,Peter 等人提出了新的解决方案: ELMo。与 Word2Vec 相比,ELMo 最大的优势在于相同单词的词向量表达不是唯一的,而是可以根据语义进行改变的。根据语义调整后的词向量更符合在当前语境中的含 义,因此一词多义的问题也就迎刃而解。
谷歌在 2017 年第一次提出了 [[Transformer]] 的概念。Transformer 是通过多层自注意力层叠加而成的深度神经网络,具有非常强大的特征提取能 力。2018 年谷歌发布了 [[BERT]] 模型。BERT 使用了 Transformer 网络来进行特征抽取,并且在预训练阶段使用双向模型来提取双向语言特征。大量实验证明, BERT 预训练模型可以极大的提升命名实体识别的精度。
2022 年提出的 BERT-BiLSTM-CRF 模型,均将注意力机制与 RNN 相结合; 神经网络提取句子特征,利用注意力机制解决长距离依赖问题,有效提高了模型的整体识别能力。 注意力机制在命名实体识别任务中的应用拓展了命名实体识别的研究方向。
中文命名实体识别
与英文 NER 相比 ,中文 NER 涉及到分词问题。
中文命名实体识别任务也主要围绕基于单个中文字符的序列标注模型展开,但由于中文的非结构化特点,单个中文字符比单个英文单词的语言表现力弱,因此,后续研究较多将中文词汇的信息融入到字符表示中,以期通过丰富字符的语义信息,提升基于字序列标注模型的中文 NER 任务的性能。
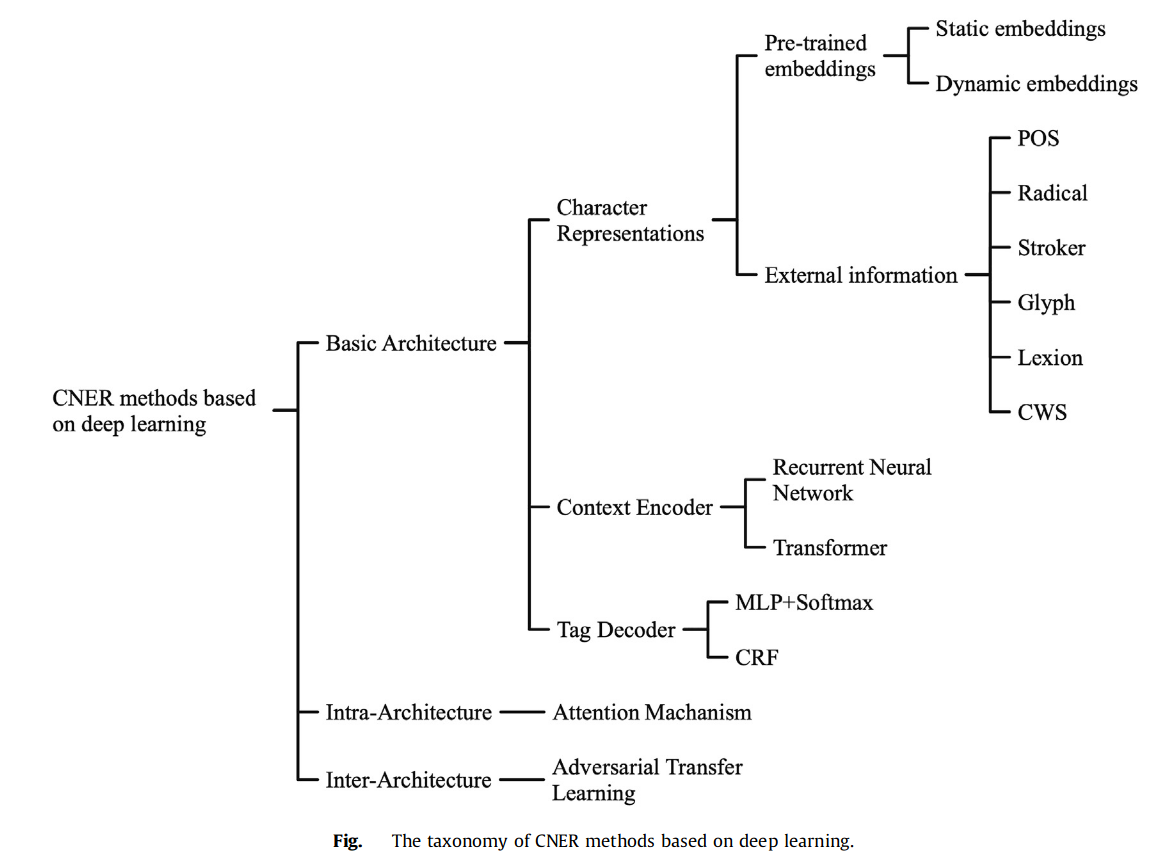
数据集
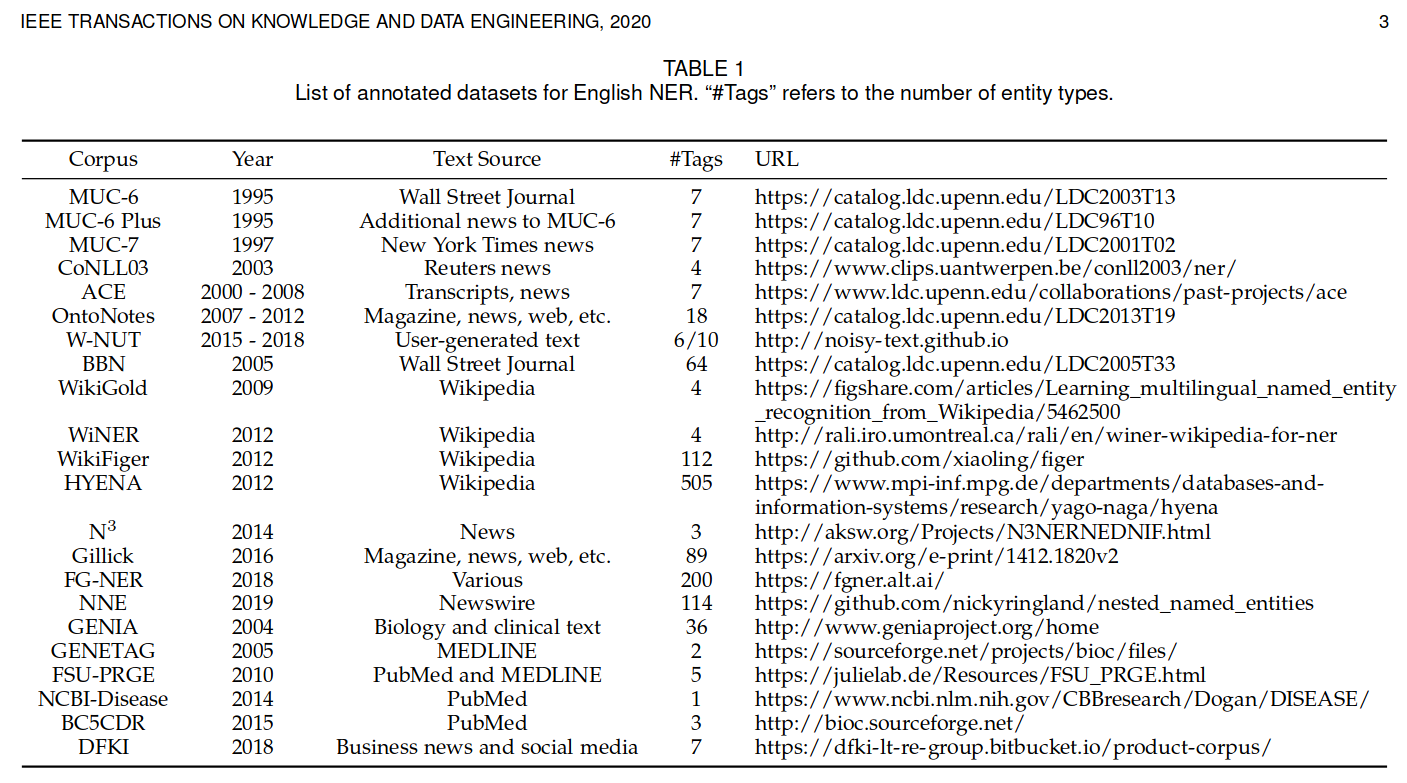
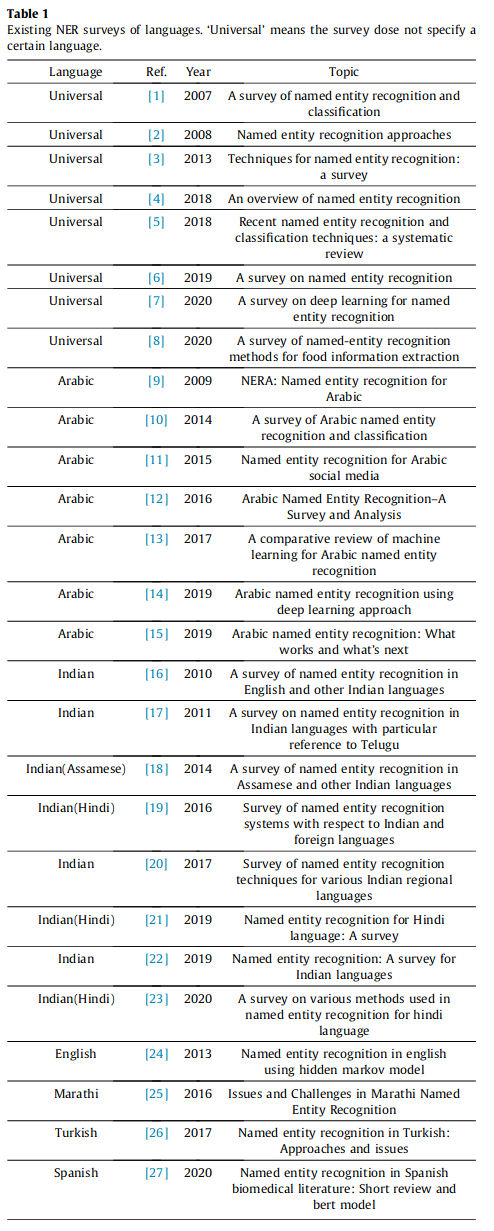
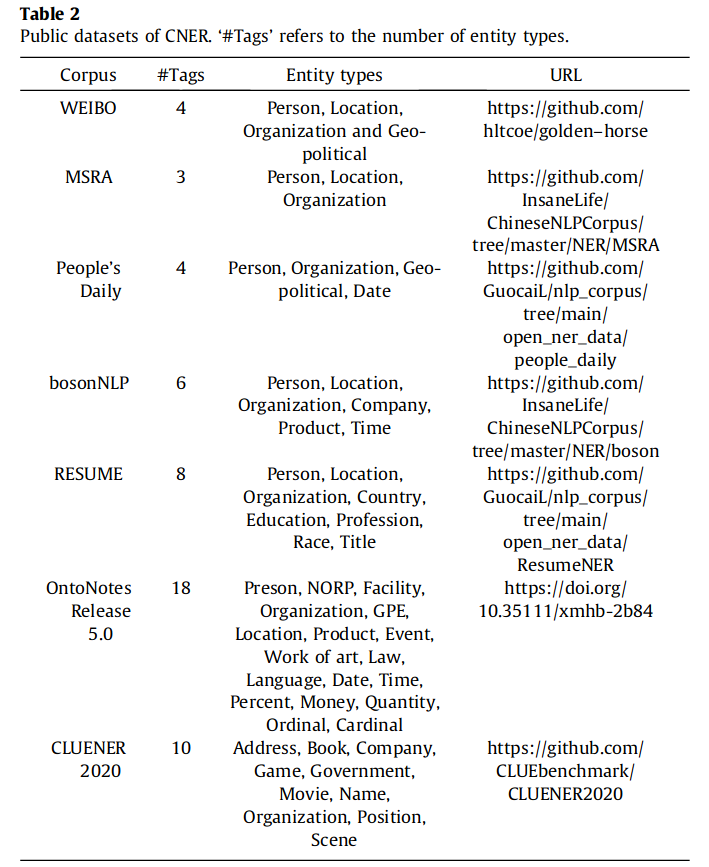
评价标准
$$F1 =2 \times \frac{precision \times recall}{precision + recall}$$
$$Precision=\frac{\#TP}{\#(TP+FP)},Recall=\frac{\#TP}{\#(TP+FN)}$$
precision 表示模型输出正确实体所占的百分比,recall 表示模型在数据集中找到正确实体的百分比 。在该任务中,普遍认为只有当实体的类型和边界都预测正确时,该实体才被认为识别正确。
部分参考文献
[1]
LIU X, CHEN H, XIA W. Overview of Named Entity Recognition[J/OL]. Journal of Contemporary Educational Research, 2022,6(5): 65-68. DOI: 10.26689/jcer.v6i5.3958 .
[2]
LIU P, GUO Y, WANG F, 等. Chinese named entity recognition: The state of the art[J/OL]. Neurocomputing, 2022,473:37-53. DOI: 10.1016/j.neucom.2021.10.101 .
[3]
赵山, 罗睿, 蔡志平. 中文命名实体识别综述[J]. 计算机科学与探索, 2022,16(2): 296-304.
[4]
徐秋荣. 基于特征融合的中文命名实体识别[D/OL]. 华东师范大学, 2022. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFDTEMP&filename=1022588714.nh&v= .
[5]
罗辉. 基于深度学习的命名实体识别方法研究[D/OL]. 重庆理工大学, 2022. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFDTEMP&filename=1022520040.nh&v= .
[6]
刘康. 面向中文微博文本的命名实体识别研究[D/OL]. 华东师范大学, 2022. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFDTEMP&filename=1022500860.nh&v= .
[7]
郑再东. 面向小样本学习的中文命名实体识别算法研究[D/OL]. 华中科技大学, 2021. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFDTEMP&filename=1021914480.nh&v= .
[8]
杨登辉. 基于深度学习的命名实体识别的研究与实现[D/OL]. 北京邮电大学, 2021. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202201&filename=1021127315.nh&v= .
[9]
徐志鹏. 基于词汇增强和多特征的中文命名实体识别研究[D/OL]. 华中科技大学, 2021. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFDTEMP&filename=1021909459.nh&v= .
[10]
李猛, 李艳玲, 林民. 命名实体识别的迁移学习研究综述[J]. 计算机科学与探索, 2021,15(2): 206-218.
[11]
何玉洁, 杜方, 史英杰, 等. 基于深度学习的命名实体识别研究综述[J]. 计算机工程与应用, 2021,57(11): 21-36.
[12]
曾祥极. 数据干预增强的命名实体识别方法研究[D/OL]. 浙江大学, 2021. https://kns.cnki.net/KCMS/detail/detail.aspx?dbcode=CMFD&dbname=CMFD202201&filename=1021830690.nh&v= .
[13]
LI J, SUN A, HAN J, 等. A Survey on Deep Learning for Named Entity Recognition[M/OL]. arXiv, 2020. http://arxiv.org/abs/1812.09449 .