【NLP】粗读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
粗读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[TOC]
BERT 可以在一个比较大的数据集上,训练好比较深的神经网络(预训练模型),使其应用在很多 NLP 的任务上面,简化了训练,并提升了性能。
标题
解释一下 Pre-training,如果在一个大的数据集上训练好一个模型,但该模型主要目的是运用在另一个别的任务(叫做 trainging)上的话,那么训练该模型的任务就是 Pre-training。
Deep 很好理解,就是深。
Bidirectional 意思是双向,文后有写。
Transformers 请见 [[Transformer]]。
总结,就是 BERT 这个模型,是一个深度双向的 Transformer,用来做针对语言理解的预训练模型。
摘要
BERT 是 Bidirectional Encoder Representations from Transformers 的简写,和标题不一样,怀疑是为了和 ELMo 一样凑芝麻街.
第一段写了,BERT 是用来设计去训练深的、双向的表示,使用的是无标记的数据,联合的是左右双边的上下文信息。由于 BERT 设计精妙,所以只需要添加一个额外的输出层,进行相应的微调,就能应用在很多任务上,而不需要对于特定任务做大量修改。
第二段放出了其在 11 个任务上的 SOTA,注意,作者同时写出了绝对精度,以及与其它模型相比提升的相关精度。
导言
NLP 里面预训练已经开始流行,譬如 [[NER]] 领域,BERT 并不是第一个提出的,毕竟 CV 里面运行得很多了,但 BERT 是 NLP 里做得最优秀。
在针对下游任务使用预训练模型做特征表示的时候,一般有两种策略,一种是基于特征的,一种是基于微调的。这两个方法在预训练的时候,都是使用相同的目标函数,都是一个单向的语言模型。
基于特征的,代表作是 [[ELMo]],用的是 RNN 架构,对每一个下游的任务,构造一个跟当前任务相关的神经网络,预训练好的特征表示,会作为额外的特征,和原本的输入一起放进网络里。
基于微调的,代表作是 [[GPT]],减少对特定任务的参数,把预训练好的模型参数放在下游数据的时候,会微调所有参数。
接着作者讲了这些方法的局限性。特别是对于微调方法,由于语言模型是单向的,导致架构选择的时候有一些局限性。例如,在 GPT 中使用的是从左到右的架构。说人话就是,我们在看一个句子的时候,只能从做读到右。在一些任务上面,比如判断一句话的情绪、QA 之类的,从左往右看和从右往左看应该都是合法的。作者认为同时把两个方向的信息都放进来的话,有助于任务性能的提升。
BERT 将使用一个带掩码的语言模型来解决上述提到的不足。作者说是收到了一篇 1953 年论文的启发,Orz。BERT 每次会随机得挑选一些词元,然后盖住,目标函数就是预测出那些被盖住的词元,李沐老师说这是完形填空。还使用了“下一句预测”任务,即挑出两个句子,回答句子是否相邻,以此来学习句子层面更高的信息。
BERT 有三个贡献:
- 展示了双向模型的重要性;
- 预训练减少了特定任务架构的精心设计,作为第一个基于微调的模型,在句子层面和词元层面都取得了 SOTA;
- 开源!开源!开源!
读完导言,可以发现是摘要的扩写版本。讲了 BERT 跟 ELMo 和 GPT 的区别。ELMo对上下文进行双向编码,但使用特定于任务的架构;而GPT是任务无关的,但是从左到右编码上下文;ELMo 用的是一个基于 RNN 的架构,而 BERT 用的是 transformer(所以改动的少);GPT 用的是从左到右的架构,而 BERT 用的是双向的;把预测未来,改成了完形填空。作者把前人的这两个工作缝在了一起,缝出了 NLP 霸主 BERT。
相关工作
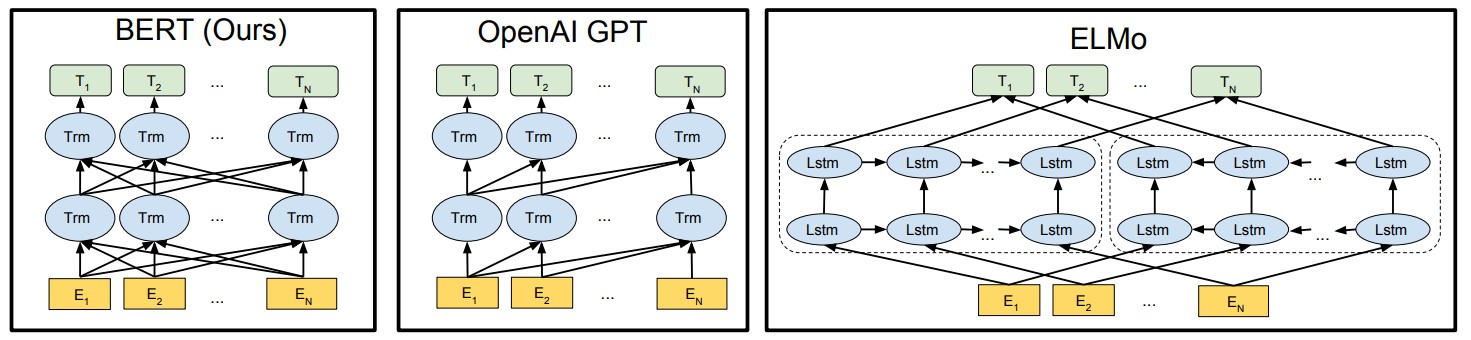
非监督的基于特征的工作。ELMo。
非监督的基于微调的工作。GPT。
有标记的数据上做迁移工作。推理、机器翻译。现在好像是更大规模、无标记的数据上学习效果更佳。
BERT
BERT 就两步,预训练 + 微调。先用预训练参数初始化 BERT 模型,再根据下游任务用有标记的数据加训。
- pre-training: 使用无标签数据训练
- fine-tuning: 所有的权重参数通过下游任务的有标记的数据进行微调
虽然每个下游任务的模型不尽相同,就架构基本一致,所以预训练与最终任务的模型结构的差别微乎其微。
架构
BERT 是一个双向多头 Transformer encoder 的堆叠组合,GPT 只用了 decoder 。
- L:Transformer 块的数量
- H:隐藏层大小
- A:多头自注意力机制头的数量
BERT 模型的复杂度,跟层数是一个线性的关系,跟宽度是一个平方的关系。每个头的维度都固定在了 64。
$$BERT_{BASE}(L=12,H=768,A=12,Total Parameters=110M)$$
输入的是字典大小,约 30 K。输出等于隐藏单元个数,为 768。作为输入进入 Transformer 块,Transformer 块内有两个单元,一个是自注意力机制,一个是后面的 MLP。自注意力机制没有可以学习的参数,但是由于使用的是多头注意力机制,把所有的输入的 K、V、Q 分别做一次投影,每次投影维度为 64,头的数量 A 乘以 64 就等于 H。而每个投影矩阵在每个头之间,合起来就是一个 H 乘 H 的矩阵;输出(组合投影的线性层)之后再做一次投影,也是一个 H 乘 H 的矩阵;加起来就是$4H^2$。MLP 有两层,一层是。综上,总参数个数为 $$TotalParameters=30K\times H+L\times H^2\times12$$
输入输出
序列可以是连续文本的任意跨度,而非实际的语言句子。在 BERT 里,序列可能是一个句子,也可能是两个打包在一起的句子。
使用了 WordPiece 做切词,把单词切成高频词、词根、词缀之类的,大概有 30000 个 token。就是把语料拆成更小的颗粒度,避免 dictionary 过大,除了 WordPiece,还有 BPE,ULM,待读。
序列开头用 [CLS] 来表示,目测是classification。
序列之间有两种方法区分。一是在每个句子后面加上 [SEP],目测是separation。二是添加一个学习嵌入层,来表示句子属于句子 A 还是句子 B。
BERT 输入格式,即给一个词元的序列,然后得到一个向量序列,进入Transformer块。序列由词元本身、所在句子、词元的相应位置组成。不同于 Transformer 的位置编码是由三角函数生成的,BERT 全是用训练得到的。

将这三个不同的 embedding 层的输出相加之和作为 encoder 输入。
预训练
逐步调整模型参数,使得模型输出的文本语义,能提现出文本的本质,起码从实验上看是这样的。
再次强调 BERT 不适用单向,然后介绍了两个无监督的任务。
MLM - 掩码语言模型
因为双向表示将允许每个单词间接“看到自己”,并且也可以在多层上下文中轻松预测目标单词。
所以,为了防止 see the future,为了深度训练双向表示,BERT 将 WordPiece 生成的词元,把其中 15% 换成 mask 标记,然后预测那些被屏蔽的标记。其中 tag 标签不做替换,只预测被屏蔽的单词而非重建整个输入。至于为什么选择 15% 呢?
这样会导致一个问题:由于微调阶段没有所谓 mask 标记,预训练和微调看到的数据会不一样。
BERT 采取了一种操作,将选中的 mask 词元,80% 照样屏蔽,10% 不变,10% 随机变成另一个 token。为什么采取这个比例呢?消融实验。
NSB - 预测下一句
为建立句子之间的联系,引入了该二分类任务。
抽取两个句子 A 和 B,50%B 是在 A 后面的,另 50% 不是。即给两个句子,问是否连在一起。
听说这个任务引起了一些争议。
预训练数据集
用了两个数据集,一个 800M 词,一个 2500M 词。
微调
因为 Transformer 中的自注意力机制,允许 BERT 通过交换适当的输入和输出来对许多下游任务进行建模,无论它们涉及单个文本还是文本对。 BERT 使用自注意力机制来统一这两个阶段,因为使用自注意力对编码链接的文本对,有效地包括了两个句子之间的双向交叉注意力。
对于不同的任务,只要把输入输出塞进来,然后进行微调。
消融实验
感觉没啥好写的。。。
去掉前面任意一个模块,都会导致精度的下降。
模型越大,效果越好。
如果是基于特征的话,文中给出了一个 [[NER]] 的对比实验,发现最好的还是基于微调的 BERT 模型,其次是基于特征的。
但也说明了,BERT 对基于微调与基于特征的实验,都是有效的。
结论
实验而非数学证明表明,使用非监督的预训练是卓有成效的。BERT 主要是把前人的结果扩展到了深的双向的架构上,使其预训练模型能够很好得处理 NLP 任务。
问题与个人理解:
为什么 Bert 用的 Encoder?
- 因为 Transformer 是一个 seq2seq 的模型,Encoder 是特征提取器 BERT 预训练只用来提取特征,Decoder 则负责把特征解码成句子
感觉 BERT 在论文里给出了一个双向的卖点,(虽然现在远不止这点),理论分析做得很少,但是实验给得相当充分,不愧是近几年来 NLP 领域的头把交椅,值得好好学习。