【NLP】粗读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
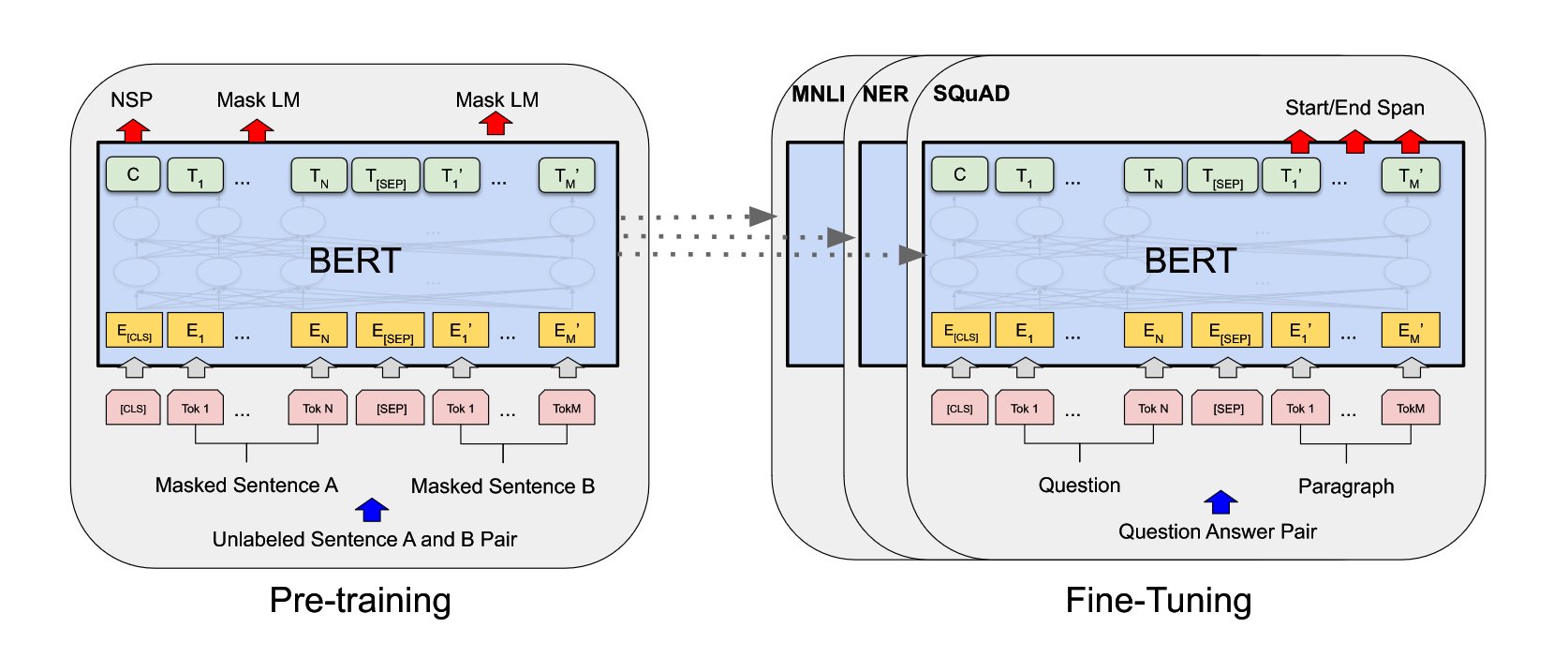
粗读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[TOC]BERT 可以在一个比较大的数据集上,训练好比较深的神经网络(预训练模型),使其应用在很多 NLP 的任务上面,简化了训练,并提升了性能。标题解释一下 Pre-training,如果在一个大的数据集上训练好一个模型,但该模型