炼丹心得
炼丹心得清空显存sudo fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh或者查找fuser -v /dev/nvidia*https://zhuanlan.zhihu.com/p/637164912nvitopnvidia-ml-py is conflict w
炼丹心得清空显存sudo fuser -v /dev/nvidia* |awk '{for(i=1;i<=NF;i++)print "kill -9 " $i;}' | sudo sh或者查找fuser -v /dev/nvidia*https://zhuanlan.zhihu.com/p/637164912nvitopnvidia-ml-py is conflict w
论文阅读计划2023-09[x] BAI J, BAI S, CHU Y, 等, 2023. Qwen Technical Report[M/OL]. arXiv[2023-10-05]. http://arxiv.org/abs/2309.16609.[x] BEURER-KELLNER L, FISCHER M, VECHEV M, 2023. Prompting Is Programming
RoBERTa: A Robustly Optimized BERT Pretraining Approachtag: #ReadPaper #NLPQ1 论文试图解决什么问题?如何使用更好的超参数与数据集对 BERT 进行充分的训练。Q2 这是否是一个新的问题?学疏才浅,不清楚,但应该是的。不谈 novelty, 自从 BERT 提出后,在其框架上做出一些改动获得一些效果,这种想法应该是显而易见
NERWikipediaNamed-entity recognition (NER) (also known as (named) entity identification, entity chunking, and entity extraction) is a subtask of information extraction that seeks to locate and classif
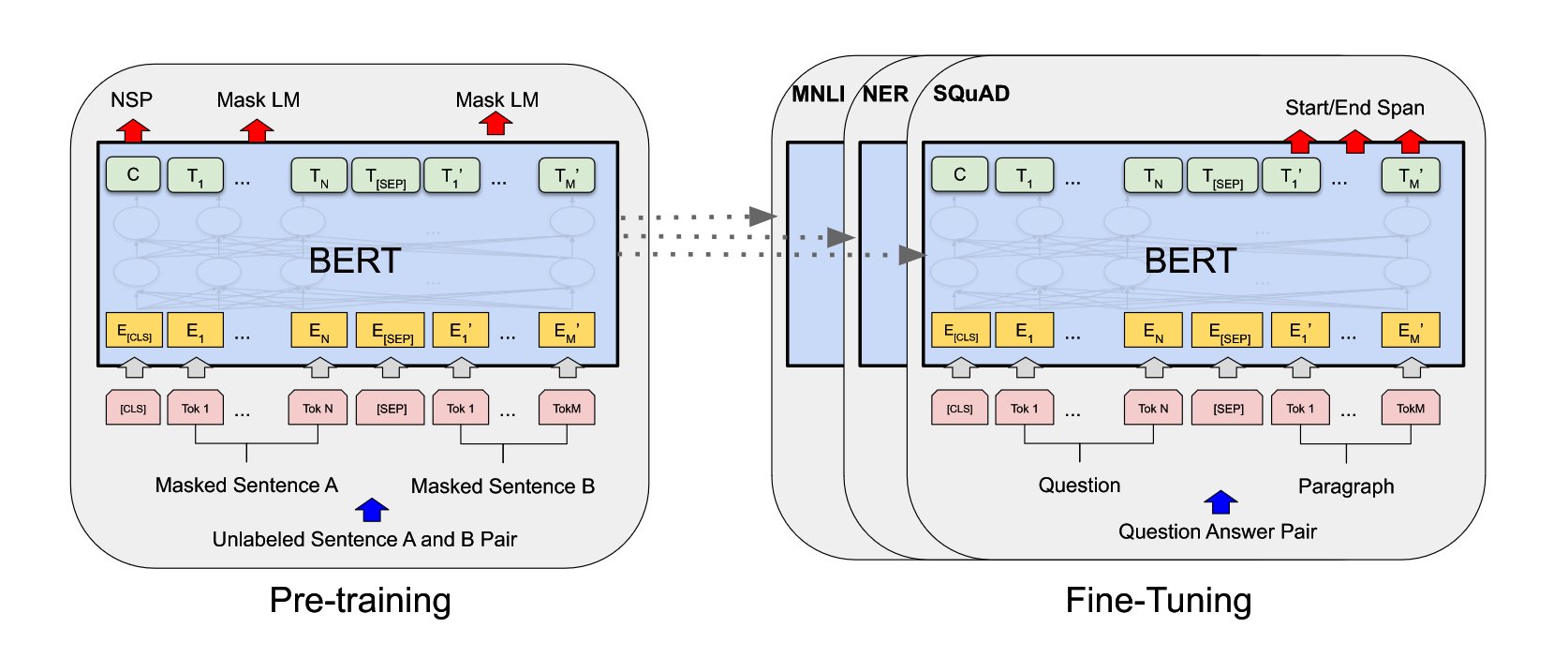
粗读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding[TOC]BERT 可以在一个比较大的数据集上,训练好比较深的神经网络(预训练模型),使其应用在很多 NLP 的任务上面,简化了训练,并提升了性能。标题解释一下 Pre-training,如果在一个大的数据集上训练好一个模型,但该模型
【NLP】初探整理自网络,感谢 OpenBMB,PaperWeekly, MLT Artificial Intelligence。有监督学习文本数据搜集和预处理将文本进行编码和表征从 one-hot 表示一个词到用 bag-of-words 来表示一段文本,从 k-shingles 把一段文本切分成一些文字片段,到汉语中用各种序列标注方法将文本按语义进行分割,从 tf-idf 中用频率的手段来表