【NLP】初探
【NLP】初探
整理自网络,感谢 OpenBMB,PaperWeekly, MLT Artificial Intelligence。
有监督学习
- 文本数据搜集和预处理
将文本进行编码和表征
从 one-hot 表示一个词到用 bag-of-words 来表示一段文本,从 k-shingles 把一段文本切分成一些文字片段,到汉语中用各种序列标注方法将文本按语义进行分割,从 tf-idf 中用频率的手段来表征词语的重要性,到 text-rank 中借鉴 page-rank 的方法来表征词语的权重,从基于 SVD 纯数学分解词文档矩阵的 LSA,到 pLSA 中用概率手段来表征文档形成过程并将词文档矩阵的求解结果赋予概率含义,再到 LDA 中引入两个共轭分布从而完美引入先验。
Word2vec 是 Word Embedding 方式之一,将词转化为「可计算」「结构化」的向量的过程。这种方式在 2018 年之前比较主流,但是随着 BERT、GPT2.0 的出现,这种方式已经不算效果最好的方法了。- 设计模型解决具体任务
大模型
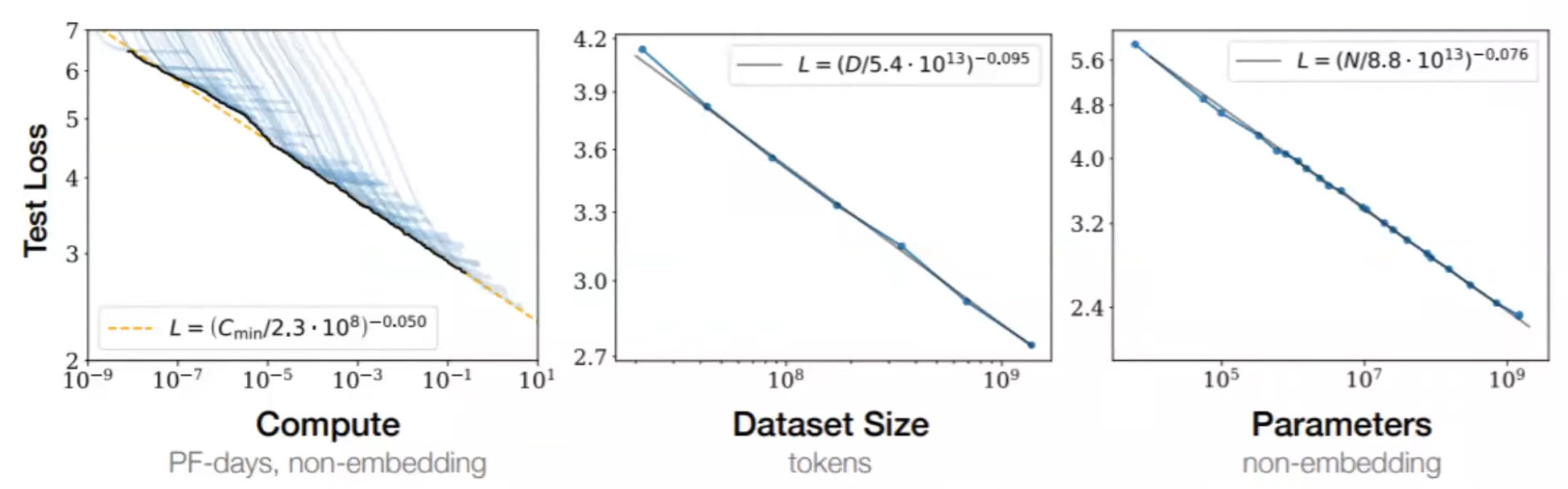
理论:大模型的基础理论是什么?
什么是大模型,GPT2/3,BERT,以及其变体。
大模型的可解释性架构:Transformer 是终极框架吗?
边际效应
来自数学非欧几何的启发
来自工程与物理的启发
来自神经科学的启发能效:如何使大模型更加高效?
内存、计算资源、时间、能耗等
如何在保证效率的前提下,压缩大模型适配:大模型如何快速适配到下游任务?
可控:如何实现大模型的可控生成?
即如何生成我们任务需要的具体的
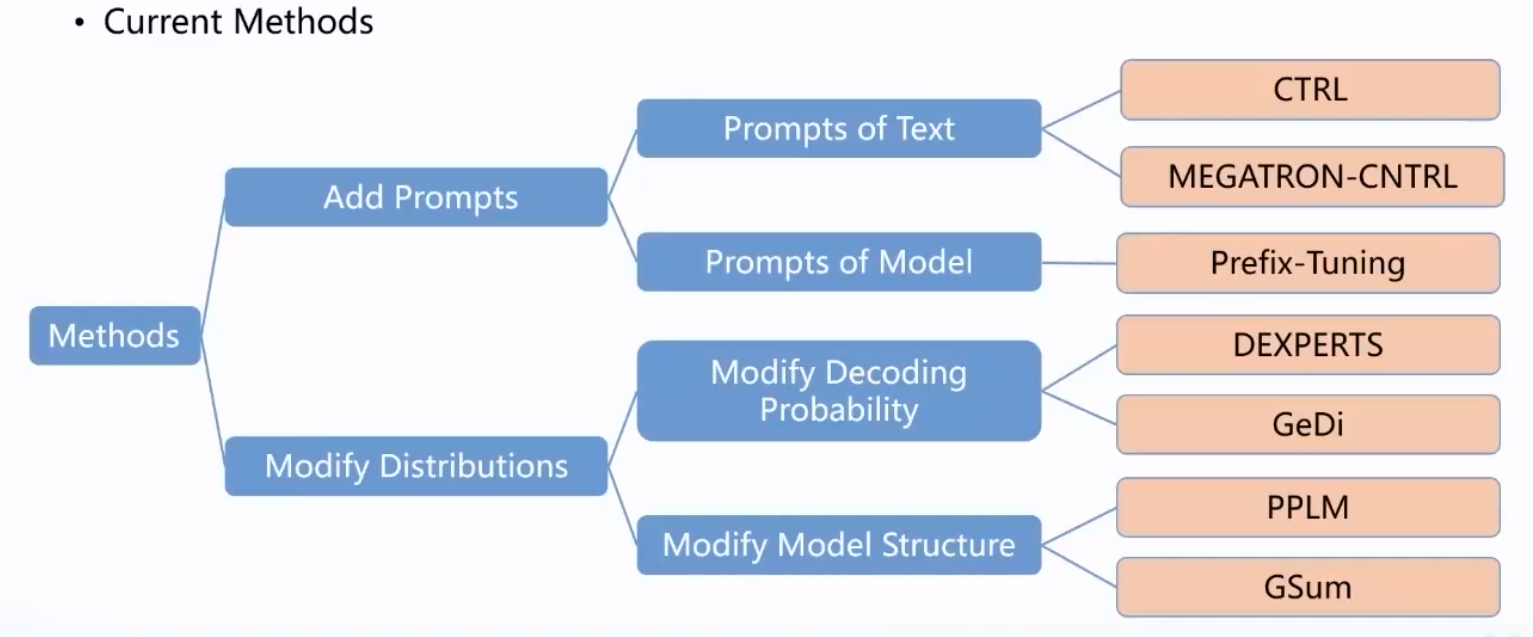
安全:如何改善大模型中的安全伦理问题?
后门与偏见
认知:如何使大模型获得高级认知能力?
学会使用搜索引擎、控制电脑
应用:大模型有哪些创新应用?
加入隐喻的知识
评估:如何评估大模型的性能?
reliable evaluation stategies
易用:如何降低大模型系统的使用门槛?
类比数据库系统、大数据分析
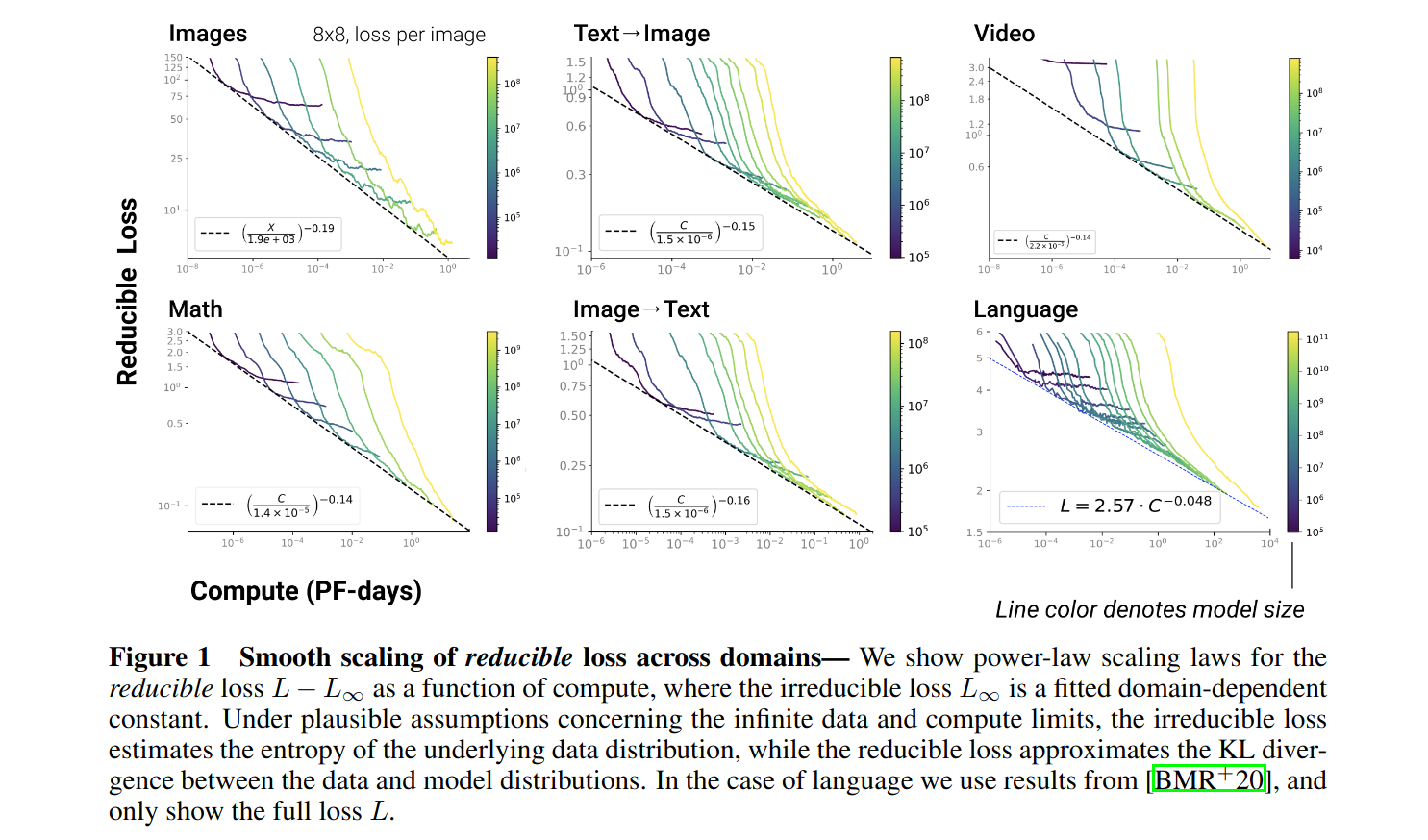
Todo
- NLP的序列标注任务,可参考 https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html?highlight=crf
- transformers 库,先主要学习使用transformers 库来做基于预训练的序列标注fintune任务,可参考 https://github.com/huggingface/transformers/tree/master/examples/pytorch/token-classification
- NLP的关系抽取任务,学习关系抽取任务的定义以及基线模型的原理,可参考 https://github.com/PaddlePaddle/PaddleNLP/tree/develop/examples/information_extraction/DuIE